The oil and gas landscape is constantly evolving, and the Open Subsurface Data Universe (OSDU) initiative stands at the forefront of this change. Its Data Platform promises to streamline operations and unlock valuable insights, but navigating its complexities can be challenging.
Since 2018, INT has been deeply involved in the OSDU journey, deploying our E&P data visualization platform, IVAAP, at every stage of the Data Platform’s development. This experience has given us unique insights and allowed us to participate in diverse deployments across scales — from proofs of concept and pilots to full-fledged production implementations. Whether you’re on AWS, Azure, GCP, or IBM Cloud, we have the expertise to guide you through your OSDU journey.
In this blog, we’ll dive deep into the insights gleaned by our team on the challenges operators face when adopting OSDU as a standard. We’ll explore the hurdles of connecting legacy applications and data with the platform and offer practical strategies to navigate this transformation and unlock its true value.
Overcoming Ingestion Challenges
While data ingestion is essential for unlocking OSDU’s power, hidden problems often lurk beneath the surface. Our experience across various implementations reveals a recurring issue: data definition and design flaws only surface after data is already ingested. This often stems from the lack of readily available visualization tools during the ingestion stage. Essentially, ingesting data “blindly” can lead to undetected errors that later derail progress.
The key to overcoming this challenge lies in early detection and proactive correction. By integrating data visualization tools like IVAAP directly into the ingestion process, we can identify issues like incomplete data sets and incorrect metadata in real time. This shift from “ingest first, fix later” to “visualize, identify, correct” can significantly streamline the process and prevent downstream complications.
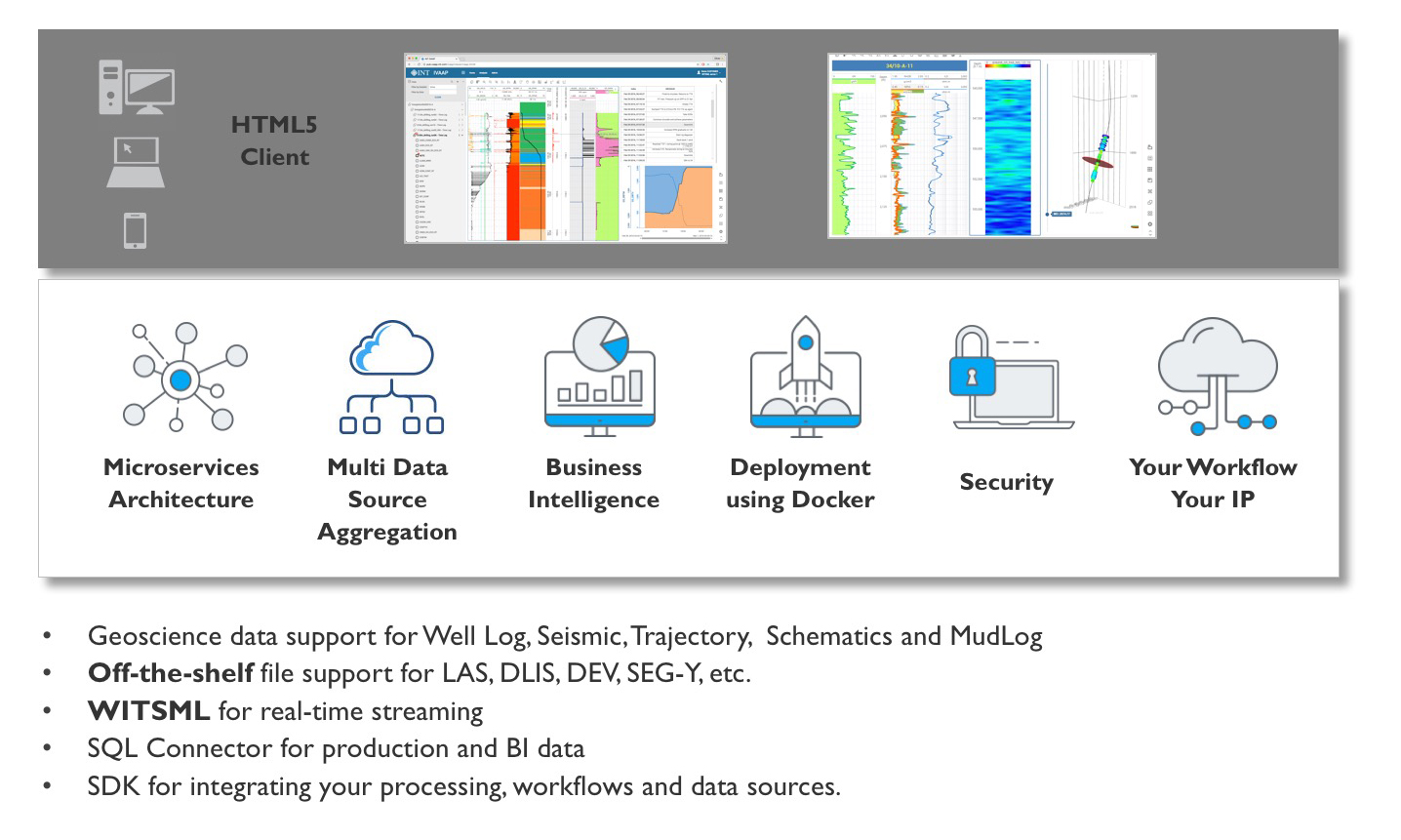
Hence, it becomes essential to have a means of visualizing and quality-checking the data as early as possible in the process when dealing with the vast number of fields in OSDU. Some parameters essential for consumption may not be explicitly required in the specifications. As a native OSDU viewer, IVAAP Data Visualization platform has been used to mitigate this risk by enabling users to perform sanity checks and validate the quality of the data throughout the ingestion process to start assessing it even during the data design phase.
Simply displaying ingested data in a web browser early on can significantly improve error detection and streamline the entire process. In simple terms, a recipe can look right on paper, but having a way to taste it before serving it to 100 guests is a safer incremental approach.
Data Mapping and Enriching the OSDU Data Model
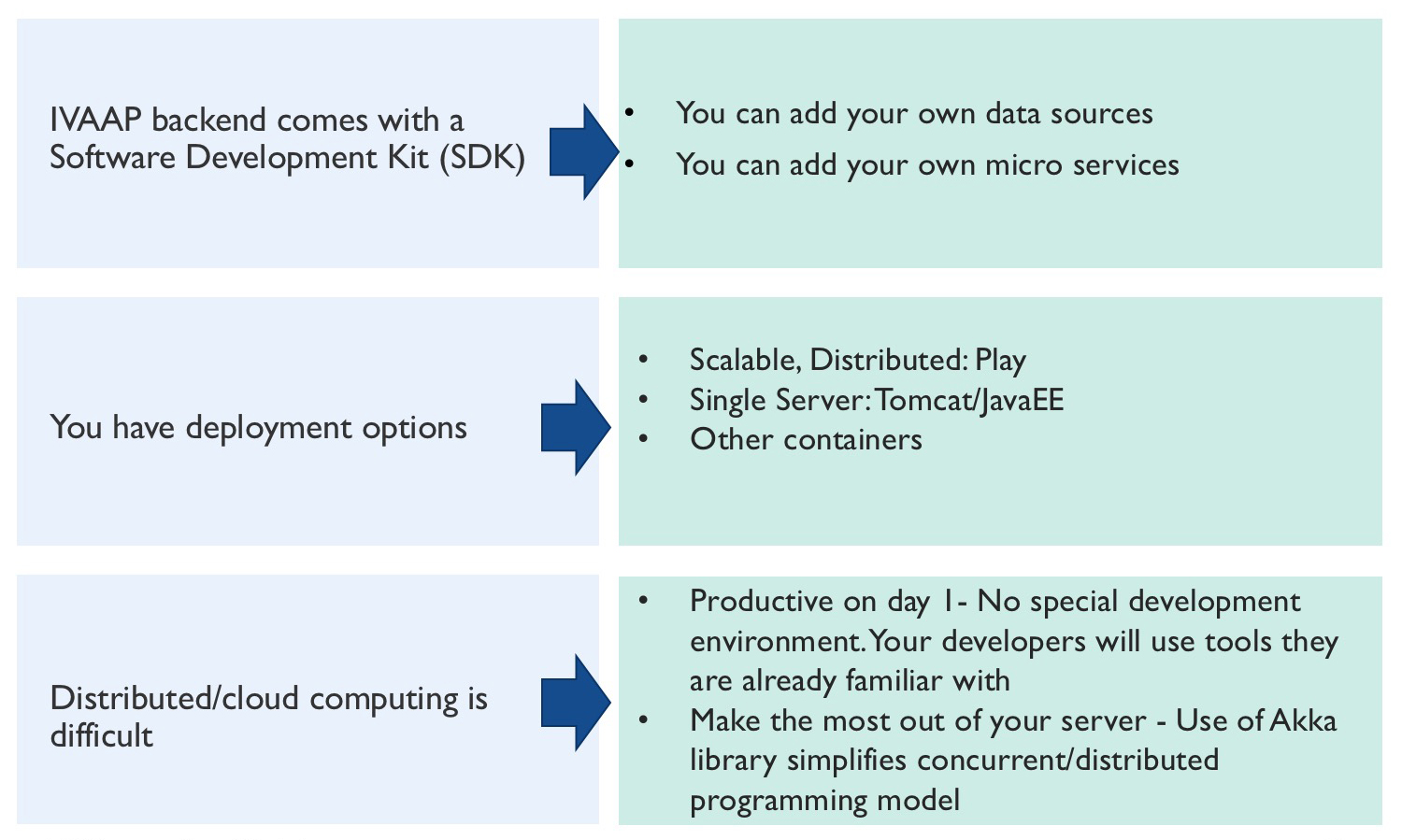
While operators embrace the standardized data models offered by OSDU, they also require flexibility to manage their unique data needs. This is where extensions come in, allowing operators to add custom metadata and data elements essential for their specific operations, geological decisions, and analysis.
However, introducing extensions can increase the complexity of OSDU adoption. Integrating these extensions requires all applications in the data pipeline and consumption ecosystem to be not only OSDU-compliant but also adaptable to exposing these unique data elements. This applies to both the submerged “iceberg” (foundation, ingestion, enrichment, infrastructure) and the exposed “tip” (user access, consumption, and visualization).
Our experience shows that leveraging IVAAP SDKs effectively addresses this challenge. They enable extending and enriching the OSDU data model with client-specific requirements, ultimately presenting users with “their data” tailored to their workflows.
Connecting Non-OSDU Data, Legacy Applications with OSDU-Ready Data
While the promise of OSDU is clear, migrating all applications overnight isn’t feasible for many oil and gas companies. Many crucial legacy applications might take years to be fully “OSDU-ready” — and may never be.
The OSDU Forum is making significant strides in standardization, but it’s an ongoing process with frequent updates and not all data types are currently supported. This can create a temporary gap between those ready for OSDU and those still relying on legacy systems.
The key challenge is preventing information silos during this transition. You might have some systems offering partial OSDU-ready data while others house crucial non-OSDU data. This fragmentation can negate the benefits of OSDU.
The temptation to stay on the sidelines, waiting for a perfect transition, is understandable. However, delaying adoption can hinder your ability to leverage the transformative power of OSDU. Instead, consider proactive solutions that can bridge the gap while providing a full picture of the entire data universe of interest.
The approach here is to take the data where it is. Data in the oil and gas industry can often be spread across different databases. To bridge this gap, companies can leverage two key strategies:
- Native Applications: Utilize existing applications that seamlessly integrate with your legacy systems, allowing you to access and utilize their data within the OSDU environment.
- OSDU-Friendly Applications: Choose applications designed to work harmoniously with OSDU, enabling data aggregation and interaction between OSDU-ready and non-OSDU data.
This is, for instance, what IVAAP does with its back-end data connectors and SDK. Aggregation capabilities, pivotal to bridging the OSDU/non-OSDU gap, also enable deeper interoperability. An example of this is the integration of SLB’s DELFI platform with INT’s IVAAP, which connects applications and workflows, making them accessible to all users and enabling team members to build common workspaces for data, data models, and interpretations while respecting proprietary information boundaries and connecting them with OSDU.
Bridging the gap between legacy applications and OSDU’s standardized data universe can be a complex challenge. Instead of forcing legacy data into a new mold, platforms like IVAAP and SLB DELFI embrace an “integrate to exist” approach. DELFI acts as a data hub, connecting these disparate databases and applications through native integrations and OSDU-friendly tools like IVAAP. This enriches the workflow with advanced visualization and data interactions, unlocking the full potential of your data universe.
Navigating the Transition from On-Premise to Cloud
While cloud adoption is a driving force in digital transformation, not every company can make a complete jump immediately. Local regulations, connectivity limitations, and data residency requirements can create concrete roadblocks to full cloud migration and, consequently, OSDU Data Platform adoption.
Fortunately, the Cloud Provider and ISV OSDU community are actively exploring various solutions to address these challenges and offer flexible deployment options. One such example is deploying IVAAP on IBM Red Hat OpenShift, which allows for a robust on-premise alternative to a full cloud solution. IVAAP supports on-premise deployments natively, whether for the standard or the OSDU configuration.
Once the on-premise concerns are addressed, transitioning efficiently is crucial to avoid unnecessary costs. A hybrid solution connects both on-premise and cloud data sources and offers a flexible approach. Data aggregation and co-visualization become key components of this transition, allowing operators to harness the benefits of cloud infrastructure while maintaining their on-premise systems during the migration.
Challenges in the OSDU Business Model
Creating a healthy ecosystem of buyers and sellers within OSDU is essential for its long-term success. Increased adoption leads to deeper expertise and better utilization. To achieve this, operators must transition from proof of concept (POC) stages into production.
Encouraging operators to invest in sharing their expertise, domain knowledge, experiences, and requirements, along with co-financing initiatives, is crucial for building a thriving OSDU ecosystem. In the same way that the energy transition cannot just rely on operators but requires the contribution of consumers and governing bodies, the OSDU transition cannot rely just on the R&D backbone of ISVs (Independent Software Vendors).
The past four years have taught us valuable lessons about liberating data. There is plenty more to do, learn, and share amongst this very smart and dedicated community. This is an exciting time to be in this industry and shaping its future.
From an INT perspective, one challenge we commonly encounter is that visualization is often thought of only at the end of the process. Thinking about consuming the data at the end of a very linear process represents significant risks such as poor user adoption, missed data, and delays, jeopardizing the business value of adopting OSDU.
We have observed that the most successful projects integrate user experience, data search, and visualization early on alongside core workstreams like data infrastructure, definition, and ingestion. Each workstream even used data visualization as a core function to test the quality of their activity and maximize its success.
Encouraging ISVs and Solution Creators
Finally, driving the participation of ISVs and solution creators in building for OSDU is vital. Operators can play a significant role by encouraging ISVs to design more open systems rather than relying on proprietary technology. This openness facilitates collaboration and accelerates the transition towards OSDU adoption.
Navigating OSDU deployments requires a strategic approach that addresses legacy systems, data mapping, and cloud migration complexities. By leveraging tools like IVAAP and fostering a collaborative spirit among operators, ISVs, and solution creators, the oil and gas industry can unlock the full value of OSDU: a more efficient and interconnected future.
Visit us online at int.com/ivaap for a preview of IVAAP or for a demo of INT’s other data visualization products.
For more information, please visit int.flywheelstaging.com or contact us at intinfo@int.com.