With the explosion of storage capacity, cloud computing, and bandwidth availability, a trend has emerged in the oil and gas industry over the last few years. Data that was previously aggregated and discarded is now maintained and stored, creating an opportunity for the industry. Coupled with new advancements in machine learning and Al, this data availability is poised to drive more data driven decision making in well planning, drilling & completions, and well operations.
After our conversations with major operators over the last few months, we realized that the concept of a data lake is still pretty new and can be perceived differently. We thought this would be a great opportunity to explain what this technology approach is and its benefits and how major operators can leverage INT’s enterprise data visualization platform to help garner insights from geoscience data in the cloud.
What is a Data Lake?
The idea behind a data lake is that as businesses gather more data, this data cannot be used the same way it has been used in the past. Databases are not a good fit for big data, not just because of the size of that data but also because this data cannot be normalized. A Data Lake is a large storage of raw data where each data point is stored in its native format, along with relevant metadata.
This approach solves a problem that the oil and gas industry has faced for a long time. Despite industry efforts to standardize data formats, these formats are loosely followed and too limited to contain all information related to a particular seismic survey or an oil field. Keeping the data as is makes your job of extracting valuable information difficult. And if you opt to normalize that data, you inevitably lose information. The concept of Data Lake opens the possibility of both keeping your original data while allowing its exploitation.
How do you exploit data from a Data Lake?
When you add files to your Lake, you carry along these files’ relevant metadata. When the right set of metadata is provided, you can search your data from this set. For example, if each document is geo-referenced, you can search for all documents relative to a geographical area.
How is the concept of Data Lake different from a search engine?
Search engines can’t really exploit files in SEG-Y or LAS formats. And even for well-known formats such as PDF, search engines have no awareness of which attributes of a PDF file are important to you. For example, if your metadata indicates that a file documents the characteristics of a well at a particular location, a Data Lake will allow you to find this file just by selecting the right region of interest.
How are cloud providers helping with Data Lakes?
Microsoft Azure, Amazon Web Services, and Google Cloud have developed a wide range of products and components to facilitate the creation and use of data lakes, such as nearly infinite storage, artificial intelligence, and machine learning to provide a seamless way to ingest and consume your data. The technology behind such advanced indexing and analytics cannot be reproduced in-house—you need a world-class partner.
How is INT helping with Data Lakes?
INT helps in two ways: We have unique experience in the industry. Working with so many actors, we have acquired the knowledge required to read multiple data formats, even when these formats are not strictly followed. Our tools facilitate the extraction of the metadata required for the Lake to function as intended, and not as a “swamp.”
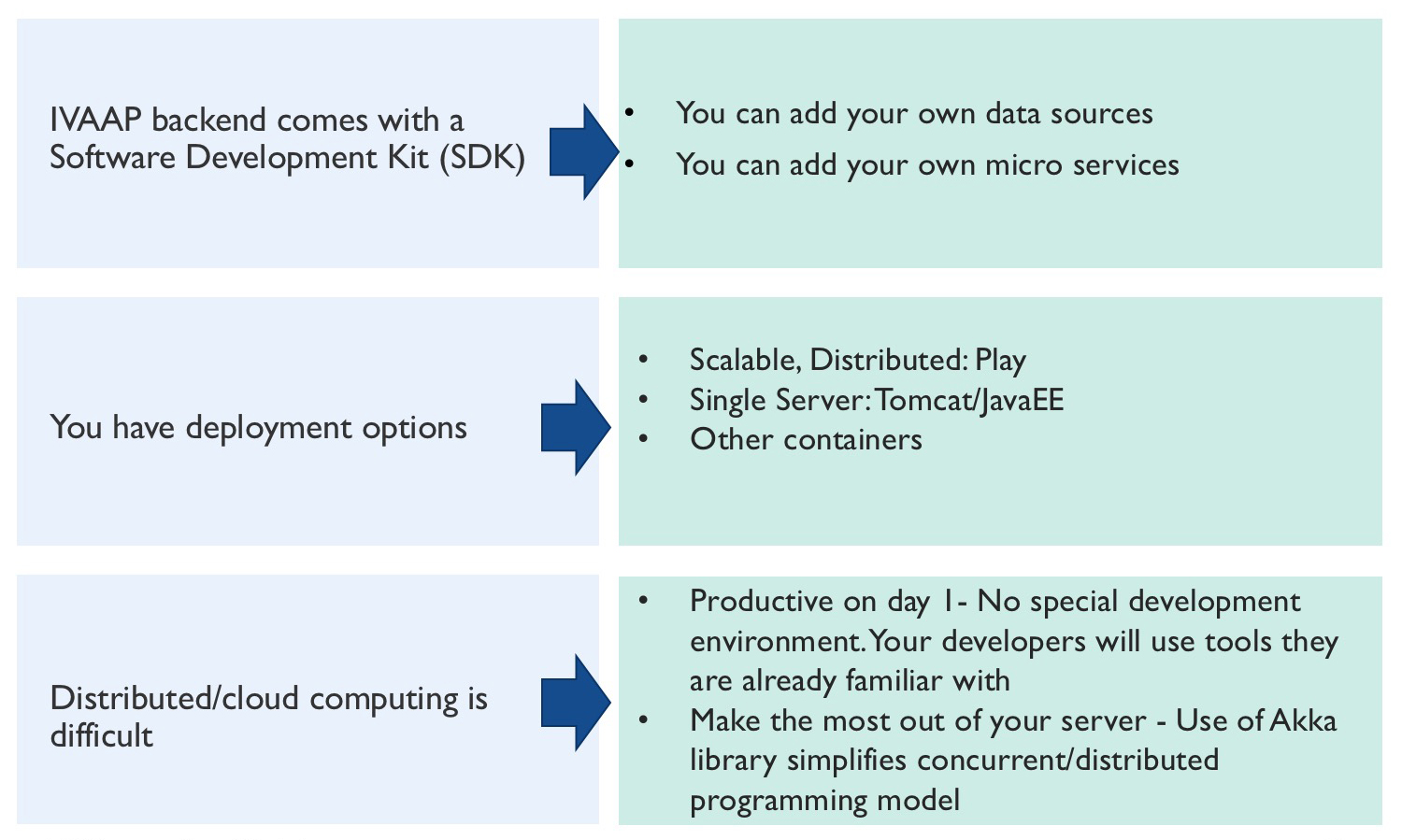
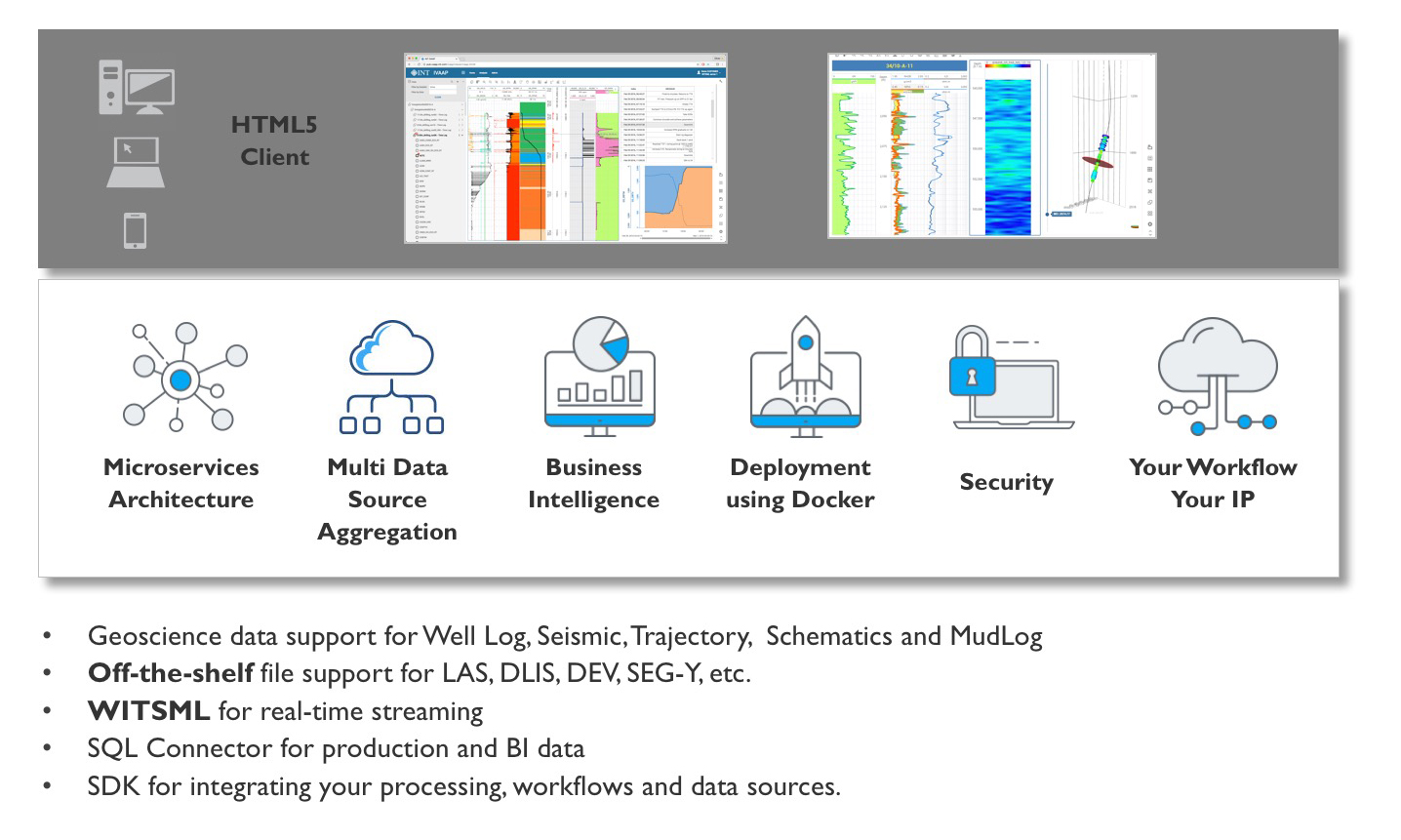
And, of course, our visualization technology is what makes it all possible, all from the comfort of your browser. Our IVAAP Enterprise Cloud Viewer allows you to visualize the datasets and documents stored remotely in your Data Lake. You’ll see how you can start from a map and drill down all the way down to the log curves of a well found on that map. In the same screen, you’ll be able to review PDF reports for that well and navigate through the slices of the matching seismic survey as if it was stored locally.
For more information about our enterprise data visualization solutions, visit the IVAAP product page, or contact us.