As the use cases of IVAAP grow, the implementation of the data backend evolves. Past releases of IVAAP have been focused on providing data portals to our customers. Since then, a new use case has appeared where IVAAP is used to validate the injection of data in the cloud. Both use cases have a lot in common, but they differ in the way errors should be handled.
In a portal, when a dataset fails to load, the reason why needs to stay “hidden” to end-users. The inner workings of the portal and its data storage mechanisms should not be exposed as they are irrelevant to the user trying to open a new dataset. When IVAAP is used to validate the results of an injection workflow, many more details about where the data is and how it failed to load need to be communicated. And these details should be expressed in a human friendly way.
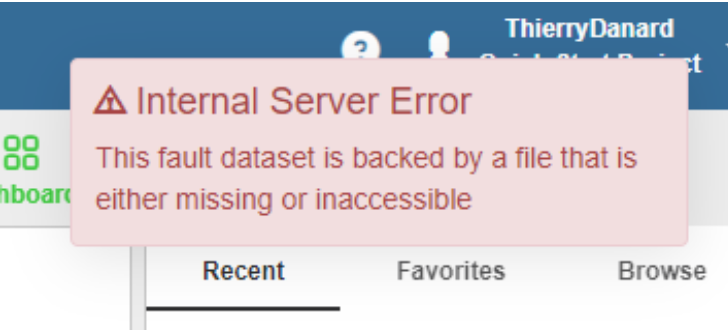
To illustrate the difference between a human-friendly message and a non-human friendly message, let’s take the hypothetical case where a fault file should have been posted as an object in Amazon S3,… but the upload part of the ingestion workflow failed for some reason. When trying to open that dataset, the Amazon SDK would report this low-level error: “The specified key does not exist. (Service S3, Status Code: 404, Request ID: XXXXXX)”. In the context of an ingestion workflow, a more human friendly message would be “This fault dataset is backed by a file that is either missing or inaccessible.”
The IVAAP Data Backend is written in Java. This language has a built-in way to handle errors, so a developer’s first instinct is to use this mechanism to pass human friendly messages back to end users. However, this approach is not as practical as it seems. The Java language doesn’t make a distinction between human-friendly error messages and low-level error messages such as the one sent by the Amazon SDK, meant to be read only by developers. Essentially, to differentiate them, we would need to create a HumanFriendlyException class, and use this class in all places where an error with a human-friendly explanation is available.
This approach is difficult to scale to a large body of code like IVAAP’s. And the IVAAP Data Backend is not just code, it also comes with a large set of third-party libraries that have their own idea of how to communicate errors. To make matters worse, It’s very common for developers to do this:
try {
// do something here
} catch (Exception ex) {
throw new RuntimeException(ex);
}
This handling wraps the exception, making it difficult to catch by the caller. A “better” implementation would be:
try {
// do something here
} catch (HumanFriendlyException ex) {
throw ex;
} catch (Exception ex) {
throw new RuntimeException(ex);
}
While this is possible to enforce this style for the entirety of IVAAP’s code, you can’t do this for third party libraries calling IVAAP’s code.
Another issue with Java exceptions is that they tend to occur at a low-level, where very little context is known. If a service needs to read a local file, a message “Can’t read file abc.txt” will only be relevant to end users if the primary function of the service call was to read that file. If reading this file was only accessory to the service completion, bubbling up an exception about this file all the way to the end-user will not help.
To provide human-friendly error messages, IVAAP uses a layered approach instead:
- High level code that catches exceptions reports these exceptions with a human friendly message to a specific logging system
- When exceptions are thrown in low level code, issues that can expressed in a human friendly way are also reported to that same logging system
With this layered approach where there is a high-level “catch all”, IVAAP is likely to return relevant human friendly errors for most service calls. And the quality of the message improves as more low-level logging is added. This continuous improvement effort is more practical than a pure exception-based architecture because it can be done without having to refactor how/when Java exceptions are thrown or caught.
To summarize, the architecture of IVAAP avoids using Java exceptions when human-friendly error messages can be communicated. But this is not just an architecture where human-friendly errors use an alternate path to bubble up all the way to the user. It has some reactive elements to it.
For example, if a user calls a backend service to access a dataset, and this dataset fails to load, a 404/Not Found HTTP status code is sent by default with no further details. However, if a human friendly error was issued during the execution of this service, the status code changes to 500/Internal Server Error, and the content of the human friendly message is included in the JSON output of this service. This content is then picked up by the HTML5 client to show to the user. I call this approach “reactive” because unlike a classic logging system, the presence of logs modifies the visible behavior of the service.
With the 2.7 release of IVAAP, we created two categories of human friendly logs. One is connectivity. When a human friendly connectivity log is present, 404/Not Found errors and empty collections are reported with a 500/Internal Server Error HTTP status code. The other is entitlement. When a human friendly entitlement log is present, 404/Not Found errors and empty collections are reported with a 403/Forbidden HTTP status code.
The overall decision on which error message to show to users belongs to the front-end. Only the front-end knows the full context of the task a user is performing. The error handling in the IVAAP Data Backend provides a sane default that the viewer can elect to use, depending on context. OSDU is one of the deployments where the error handling of the data backend is key to the user experience. The OSDU platform has ingestion workflows outside of IVAAP, and with the error reporting capabilities introduced in 2.7, IVAAP becomes a much more effective tool to QA the results of these workflows.
For more information on INT’s newest platform, IVAAP, please visit int.flywheelstaging.com/products/ivaap/